Analysis of LLM Advancement
Discuss this article on Hacker News
In this article, I’ll show the data behind the current development of LLMs and I’ll try to formulate a hypothesis on the near future of LLMs.
I. Pareto Frontier and the last two years
The Pareto frontier is the set of all the values with the highest Y value on a given X value, acting as a stepped line representing the best model for a given property at a given time.
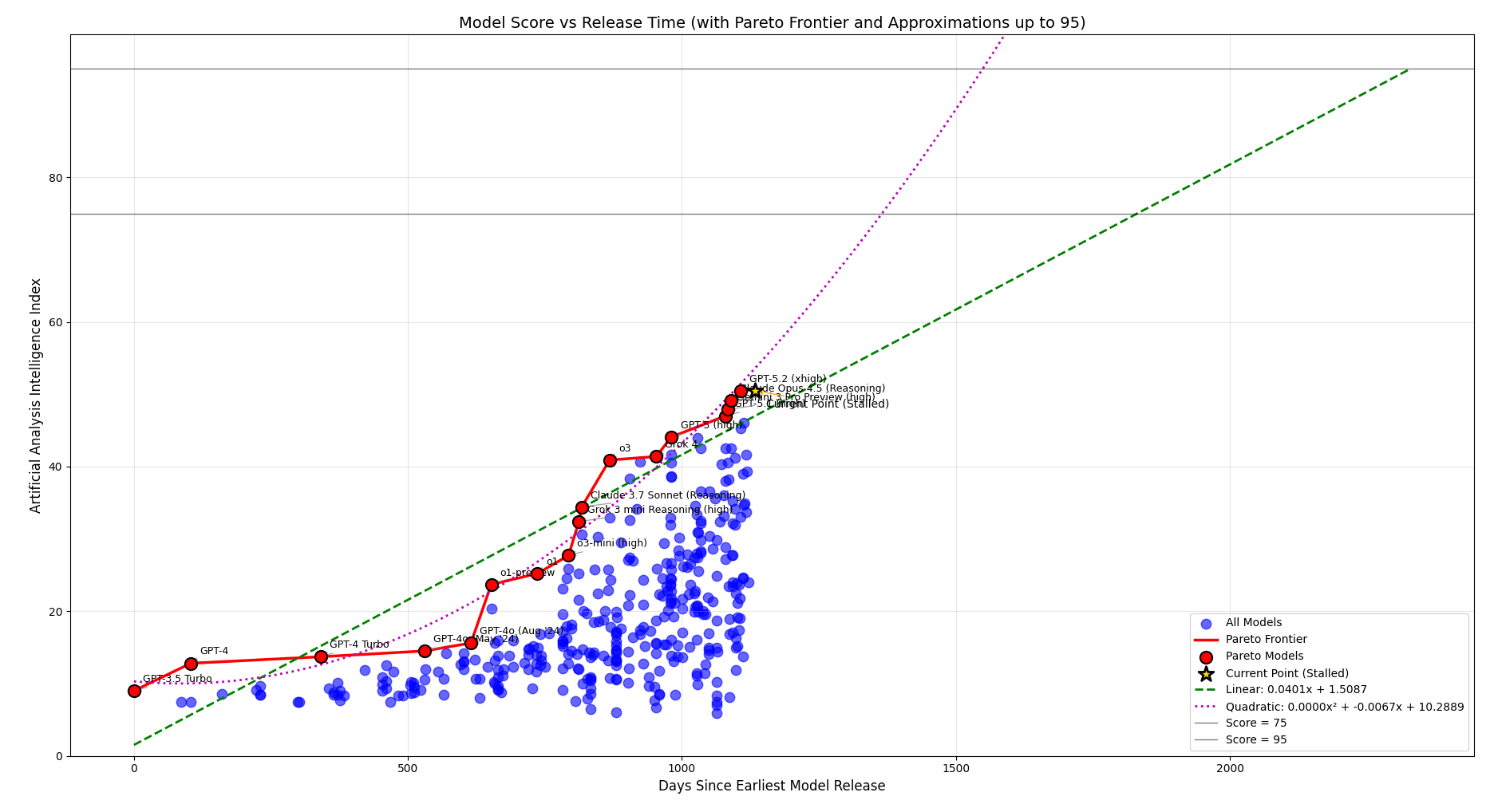
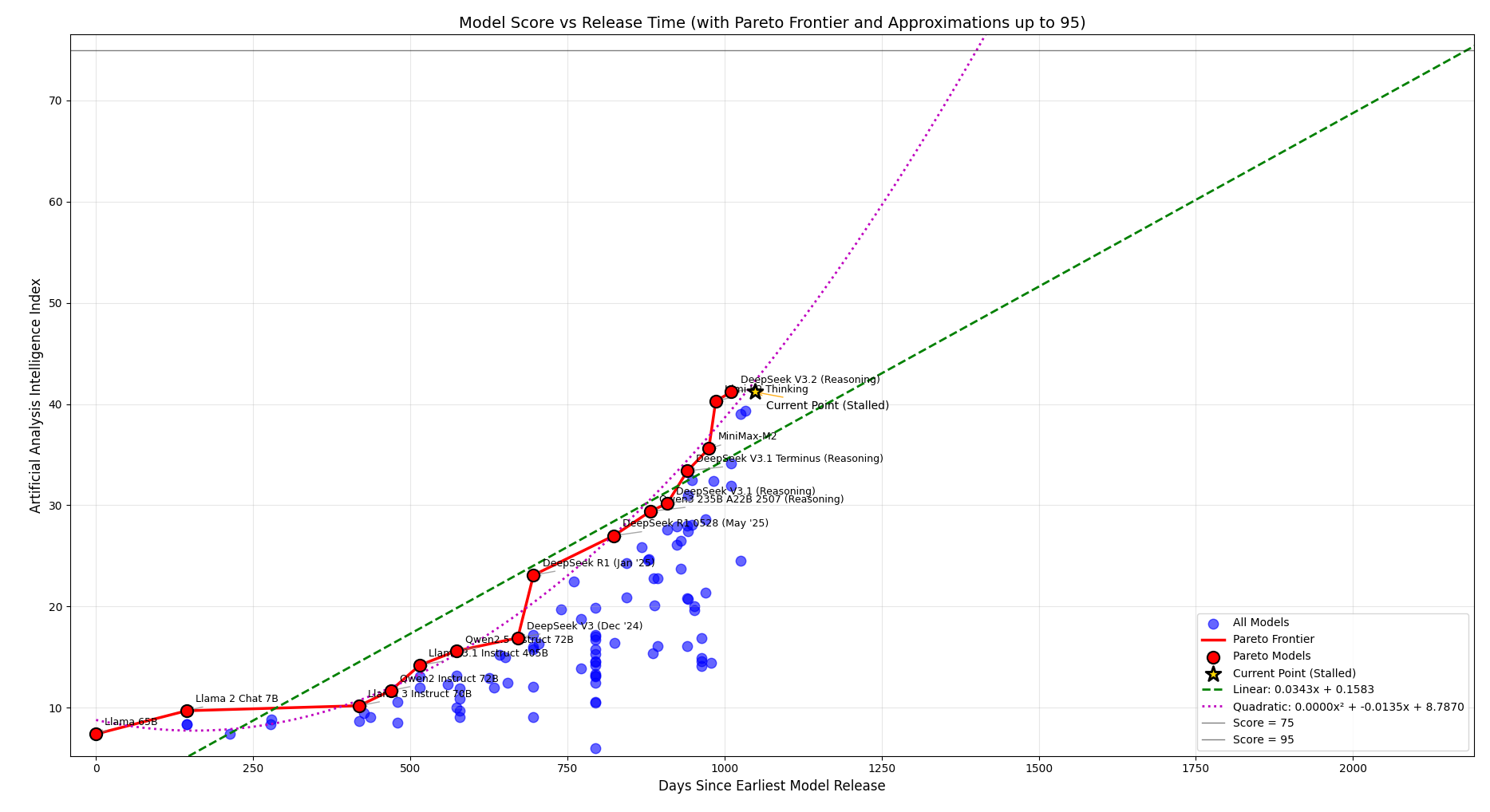
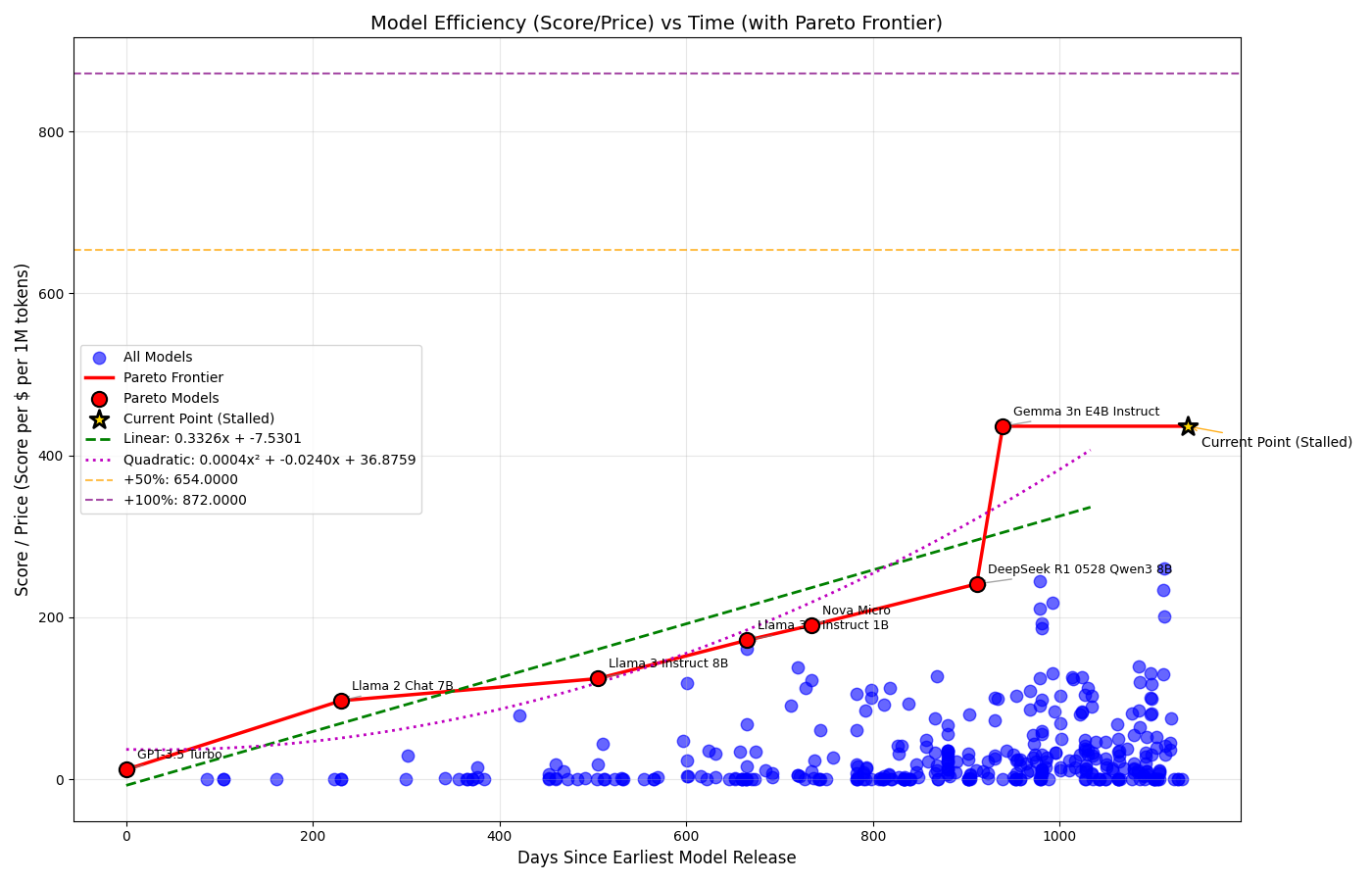
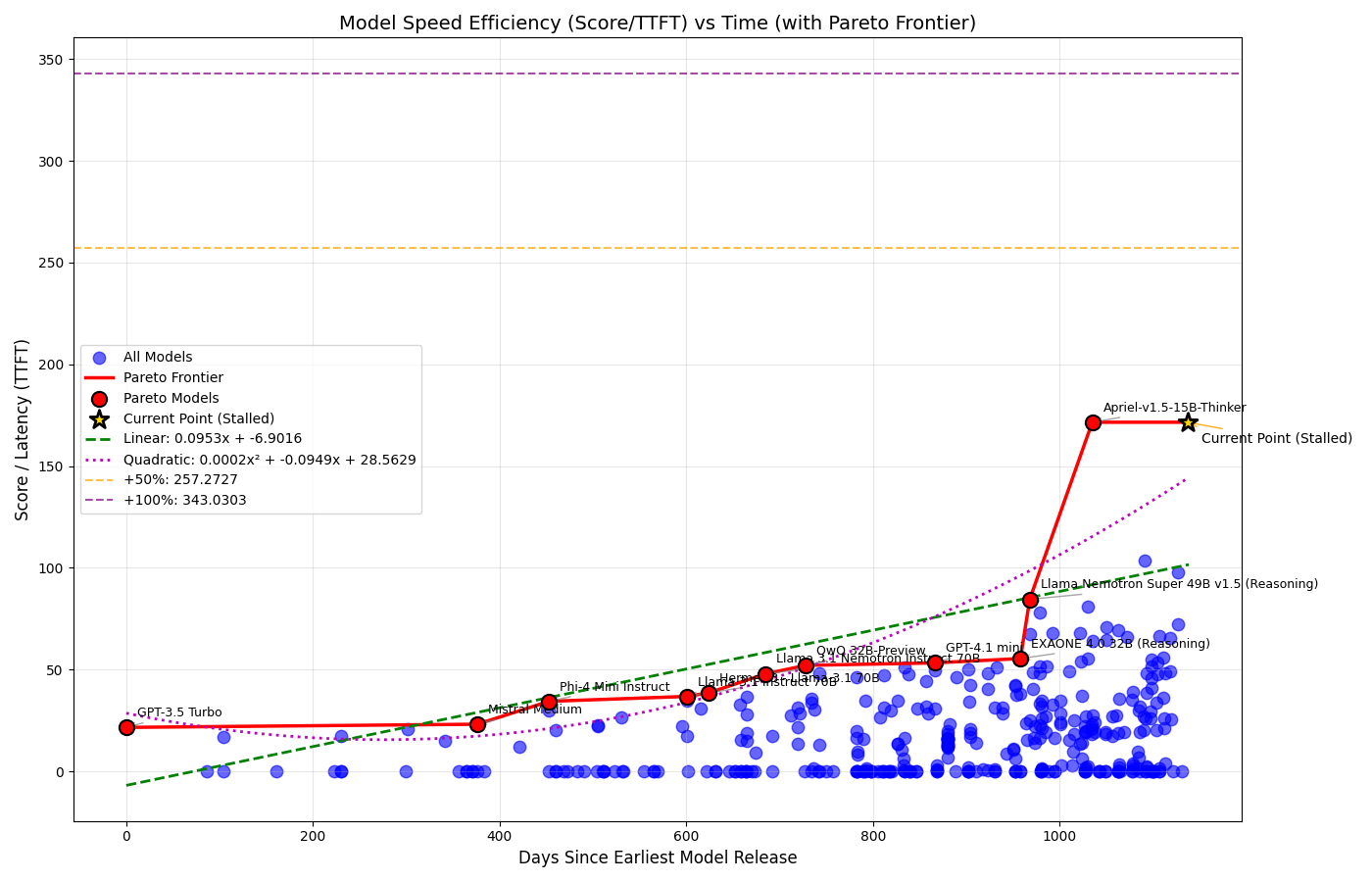
As you can see in the plots below, in the last three years LLMs have kept improving, obtaining better results on the Artificial Analysis Intelligence Index, better speeds and better prices.
In the Intelligence plots, you can also see two relevant improvements, connected to fundamental changes to the inner workings (either in training or in inference) of LLMs:
- September 2024, OpenAI’s o1 integrated chain-of-thought reasoning in order to allow for complex problem solving
- January 2025, Deepseek R1 started using reinforcement learning from verifiable rewards, in order to optimize the model to produce better chain-of-thought tokens and so resolving more complex problems.
(The Deepseek R1’s improvement is shown in the first plot with OpenAI’s o3, released in April 2025)
The rate of improvement, with around 1 major fundamental improvement per year, will be considered later for estimating the release windows for improved models.
II. The Great Doubling
We are currently at a stage where LLMs can solve complex problems, while being inaccurate in some situations; in order to talk about the future of AI, we need to set a defined objective that describes a state where LLMs can be used for real-world usage with good accuracy, price and speed.
Seeing that we need objective and pre-defined targets, we can’t use marketing terms like “AGI”, “Superintelligence”, or the famous “Singularity”, but instead we need a single relative (so percentage improvement) statistic that can be applied to all major LLM measurements (in this case, Intelligence, Speed and Efficiency).
I propose, considering the current state of AAII(~48%), FrontierMath(~30%) and of Humanity’s Last Exam(~38%), to take as the next target for real-world LLMs to double our current measurements, allowing for LLMs with accurate tool calling, long-context instruction following and frontier scientific reasoning.
In this analysis, we will consider both +50% and +100% improvements, in order to make the progress simpler to visualize and to connect to the concept of fundamental technological advancement (like chain-of-thought, as we saw before), and we’ll call the +100% improvement the Great Doubling, as it will be the last major improvement needed before an LLM capable of automating half (or more) of most office tasks.
III. Where Are We?
Well, let’s try to understand more about the advancement of LLMs, starting by downloading data from Artificial Analysis and plotting the Pareto frontier.
We then try to plot the linear and quadratic functions that are as close as possible to the given data points, obtaining:
-
an MSE of 26.88 for the linear function (RMSE = 5.18; calculated on the Intelligence plot)
-
an MSE of 7.78 for the quadratic function (RMSE = 2.79; calculated on the Intelligence plot)
Therefore, we can infer that the quadratic function is the one that best describes the Pareto frontier and that it is ~1.85x more accurate than the linear function.
(note: If you want to better understand why a quadratic function works for modelling the current scaling of LLMs, check the EpochAI studies cited at the end of the blogpost.)
Evolution of LLMs’ Intelligence
Evolution of LLMs’ Intelligence (only open-weight models)
Evolution of LLMs’ Efficiency
Evolution of LLMs’ Speed
IV. Predict the future
From the given data, we can calculate the best linear and quadratic approximations to approximate
| +50% [Linear] | +50% [Quadratic] | +100% [Linear] | +100% [Quadratic] | |
|---|---|---|---|---|
| Intelligence | Dec 2027 | Aug 2026 | Apr 2029 | Feb 2027 |
| Intelligence (open-weights) | May 2029 | Nov 2026 | Jan 2031 | May 2027 |
| Efficiency | May 2028 | Jul 2026 | Feb 2030 | Feb 2027 |
| Speed | Jul 2030 | Nov 2026 | Dec 2032 | Jun 2027 |
As we can see, the quadratic function predicts Q1 2027 for the Intelligence and Efficiency improvements and Q2 2027 for the Open-Weights and Speed improvements.
We should also consider the major advancements cited in the first section: since the introduction of CoT, Intelligence scores more than doubled, and so we can estimate that 2 more major advancements are needed, and considering the rate of 1 advancement per year, we can expect the Great Doubling to happen during 2027.
V. Conclusions
Considering everything that I said and adding one cushion trimester (to account for errors and unexpected delays), I estimate the release window of truly impactful LLMs to be in Q3 2027.
Final Notes
-
You can find the source code for the plot-generation scripts here.
-
This post will have new versions when new SOTA models are released, with updated plots and predictions.
-
Check out this Geoffrey Hinton talk if you want to understand more about the future developments of LLMs and other AI models.
-
Interesting data insights released by EpochAI:
- AI capabilities progress has sped up
- Global AI computing capacity is doubling every 7 months
- Today’s largest data center can do more than 20 GPT-4-scale training runs each month
- Open-weight models lag state-of-the-art by around 3 months on average
- The computational performance of machine learning hardware has doubled every 2.3 years
- Leading ML hardware becomes 40% more energy-efficient each year
- The power required to train frontier AI models is doubling annually
-
The Artificial Analysis Intelligence Index is limited, as it is semi-saturated and doubling the current SOTA value would bring it closer to 100%, where gains are slow and almost nonexistent; this is not because we are not getting improved LLMs, but because they managed to “beat” the benchmark. We are thinking of switching to another index, like ECI.